")
")
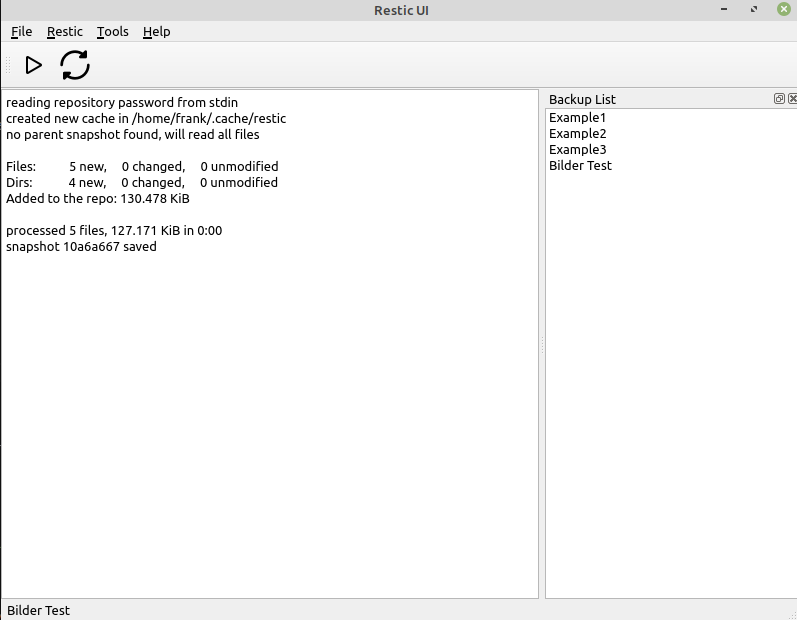
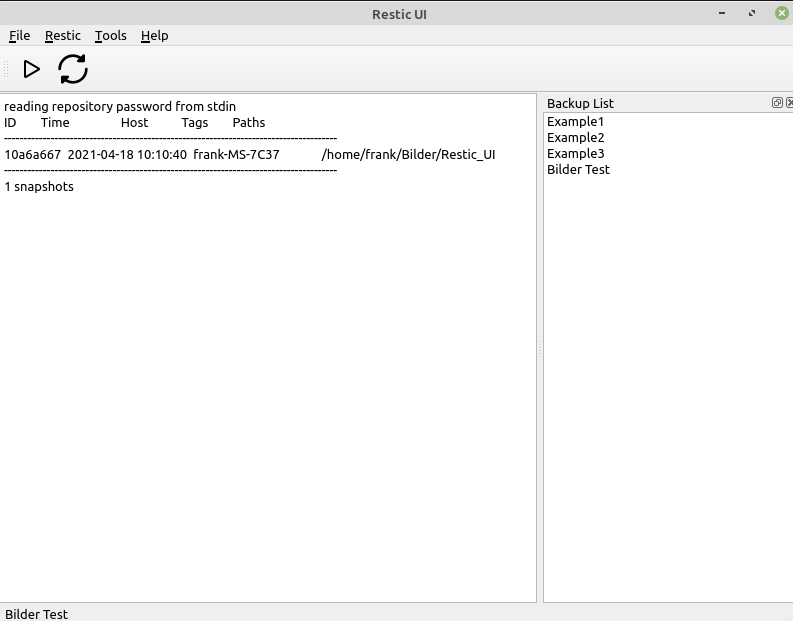
Hab ChatGPT nochmal nach der Installation auf einem Production Server befragt.
ChatGPTCertainly! Here's a short example of the steps you can follow to deploy a Flask application on a production server using Nginx and Gunicorn:
Prepare your server:
Set up a server (e.g., using a cloud provider like AWS, DigitalOcean, or a dedicated server) and ensure it has a clean, up-to-date installation of a Linux distribution (e.g., Ubuntu or CentOS).Install required software:
Install necessary software packages on your server. You'll need Python, pip (Python package manager), Nginx, and Gunicorn. You can use your distribution's package manager (e.g., apt for Ubuntu or yum for CentOS) to install these dependencies.Deploy your Flask application:
Copy your Flask application code and any required dependencies to your server.Set up a virtual environment (optional but recommended):
Create a virtual environment for your Flask application to isolate its dependencies. You can use venv or virtualenv for this purpose.Install Flask and any required Python packages within your virtual environment:
pip install flaskTest your Flask application:
Ensure your Flask application runs correctly within your server's virtual environment.Configure Gunicorn:
Create a Gunicorn configuration file (e.g., gunicorn_config.py) to specify the settings for running your Flask application. Here's a simple example: workers = 4 # Number of Gunicorn worker processes bind = '0.0.0.0:8000' # The address and port Gunicorn should listen onStart Gunicorn:
Start Gunicorn with your Flask application: gunicorn -c gunicorn_config.py your_app:appConfigure Nginx:
Create an Nginx server block (often located in /etc/nginx/sites-available) to define how Nginx should handle incoming requests. Here's a simplified example: server { listen 80; server_name your_domain.com www.your_domain.com; location / { proxy_pass http://127.0.0.1:8000; # Pass requests to Gunicorn proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; } }Enable the Nginx server block and restart Nginx:
sudo ln -s /etc/nginx/sites-available/your_config /etc/nginx/sites-enabled/ sudo nginx -t # Test Nginx configuration sudo systemctl restart nginxConfigure your DNS:
Point your domain name to your server's IP address.Secure your server (optional but recommended):
Set up SSL/TLS certificates for your domain to enable HTTPS. You can use Let's Encrypt for free SSL certificates.Monitor your application:
Set up monitoring tools and logs to keep track of your application's performance and troubleshoot any issues.These are the basic steps to deploy a Flask application on a production server with Nginx and Gunicorn. Please note that this is a simplified example, and there are many additional considerations, such as database configuration, security, and optimization, depending on your specific application and requirements. It's also important to keep your server and software up to date and follow security best practices to ensure the stability and security of your production environment.
Das werde ich doch mal ausprobieren 😎