Semaphore ist ein UI für Ansible, geschrieben mit Go & Vue.js. Beim Besuch der letzten FrOSCon 18 lernt man ja immer was dazu. Es wurde Zeit das mal auszuprobieren.
Bis jetzt habe ich meine Server, einmal in der Hetzner-Cloud zum anderen Lokal, immer mit ClusterSSH administriert. Das ist für mich völlig ausreichend, aber ich möchte gerne auch immer was dazu lernen.
Ok, dann fangen wir mal an.
Installation
Voraussetzungen
- Debian Bookworm 12 Server
- vorhandenen MariaDB Instanz
- Linux Grundkenntnisse
Ich werde nicht alles bis ins letzte Detail hier aufschreiben, aber mit Grundkenntnissen sollte man in der Lage sein, das erfolgreich umzusetzen.
Die Anleitung empfiehlt folgende Vorgehensweise.
wget https://github.com/ansible-semaphore/semaphore/releases/\
download/v2.8.75/semaphore_2.8.75_linux_amd64.deb
sudo dpkg -i semaphore_2.8.75_linux_amd64.deb
Ich ändere das ein wenig ab. Zum einen, ist die Dokumentation nicht ganz aktuell und zum anderen brauche ich kein sudo.
wget https://github.com/ansible-semaphore/semaphore/releases/\
download/v2.8.90/semaphore_2.8.90_linux_amd64.deb
dpkg -i semaphore_2.8.90_linux_amd64.deb
Danach ruft man das Setup auf
semaphore setup
und ergänzt die Abfragen. Kleiner Tipp von mir, der Web Host bleibt leer, sonst ist die Installation defekt. Für Euch getestet. Bezieht sich nur auf eine lokale Installation. Siehe meine Ergänzung zum Thema Email.
"web_host": "",
Wenn man das Ganze jetzt als User root gemacht hat, liegt die Konfigurationsdatei config.json unter /root
Das machen wir jetzt mal was sicherer. Eine Anwendung sollte ja unter seinem eigenen User laufen, kein Dienst der nicht unbedingt Rootrechte benötigt, bekommt diese auch. Also legen wir uns dafür einen User an, der heißt hier semaphore - Überraschung ")
User anlegen
Den User legen wir mit
useradd -m semaphore
an. Damit hat dieser User auch ein Home-Verzeichnis unter /home/semaphore Nun kopieren wir schon mal die config.json hierhin.
mv /root/config.json /home/semaphore
Jetzt muss der Dienst auch noch gestartet werden, dazu legen wir einen SystemD Service an.
/etc/systemd/system/semaphore.service
[Unit]
Description=Ansible Semaphore
Documentation=https://docs.ansible-semaphore.com/
Wants=network-online.target
After=network-online.target
ConditionPathExists=/usr/bin/semaphore
ConditionPathExists=/home/semaphore/config.json
[Service]
ExecStart=/usr/bin/semaphore service --config /home/semaphore/config.json
ExecReload=/bin/kill -HUP $MAINPID
Restart=always
RestartSec=10s
User=semaphore
Group=semaphore
[Install]
WantedBy=multi-user.target
Den Dienst aktivieren und starten ihn
systemctl enable semaphore.service
systemctl start semaphore.service
Danach sollte man in der Lage sein, das Webinterface aufzurufen. Hier das Beispiel meiner Proxmox VM. Passt das an Eure Gegebenheiten bitte an.
http://192.168.3.14:3000/
NGINX
Sollte man das ganze im Netz betreiben wollen, dann sollte man einen Proxy davor schalten. Hier mal ein Beispiel aus der Doku.
Man muss dann nicht
http://192.168.3.14:3000/
eingeben, um den Server zu erreichen. Es reicht dann
http://192.168.3.14
Die NGINX Beispiel Konfiguration
server {
listen 443 ssl;
server_name _;
# add Strict-Transport-Security to prevent man in the middle attacks
add_header Strict-Transport-Security "max-age=31536000" always;
# SSL
ssl_certificate /etc/nginx/cert/cert.pem;
ssl_certificate_key /etc/nginx/cert/privkey.pem;
# Recommendations from
# https://raymii.org/s/tutorials/Strong_SSL_Security_On_nginx.html
ssl_protocols TLSv1.1 TLSv1.2;
ssl_ciphers 'EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH';
ssl_prefer_server_ciphers on;
ssl_session_cache shared:SSL:10m;
# required to avoid HTTP 411: see Issue #1486
# (https://github.com/docker/docker/issues/1486)
chunked_transfer_encoding on;
location / {
proxy_pass http://127.0.0.1/;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_request_buffering off;
}
location /api/ws {
proxy_pass http://127.0.0.1/api/ws;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Origin "";
}
}
Das habe ich aktuell nicht getestet, da mein Semaphore-Server lokal steht und es auch so bleiben soll.
Für eine Anwendung, gitlab.com, brauch ich den doch im Netz. Habe das probiert und funktioniert auch. Kommt aber sicher noch ein ergänzender Beitrag von mir (Update: 20.08.23)
SSH
Wichtig ist, das der User semaphore auf alle Server, die er erreichen soll, mittels
ssh root@<DOMAIN oder IP>
connecten kann. Dazu muss die id_rsa.pub auf den Zielsystemen unter authorized_keys hinterlegt sein. Das solltet ihr kennen, wenn nicht mal kurz hier rein lesen. Zusammenfassung:
Der User semaphore muss mittels
ssh root@<DOMAIN oder IP>
connecten können!
Einrichtung eines Projektes
Wir legen ein neues Projekt an.
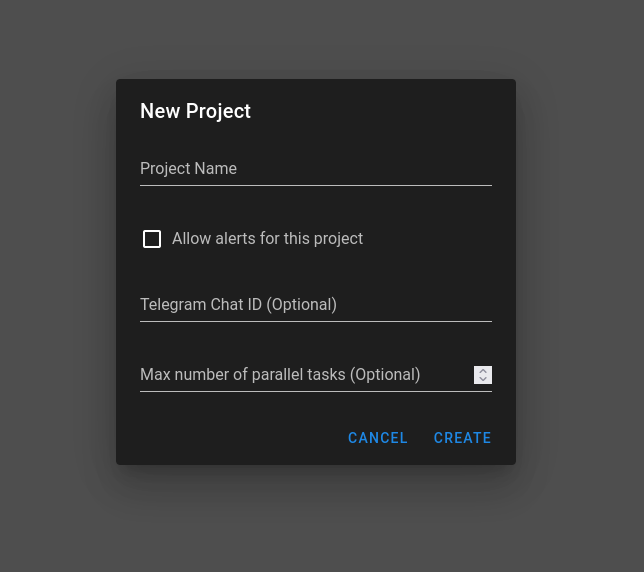
Namen eingeben, der Rest ist optional. Danach legen wir den Key an.
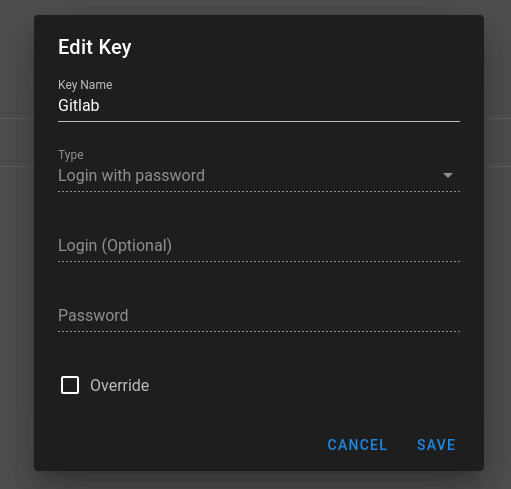
Key Store
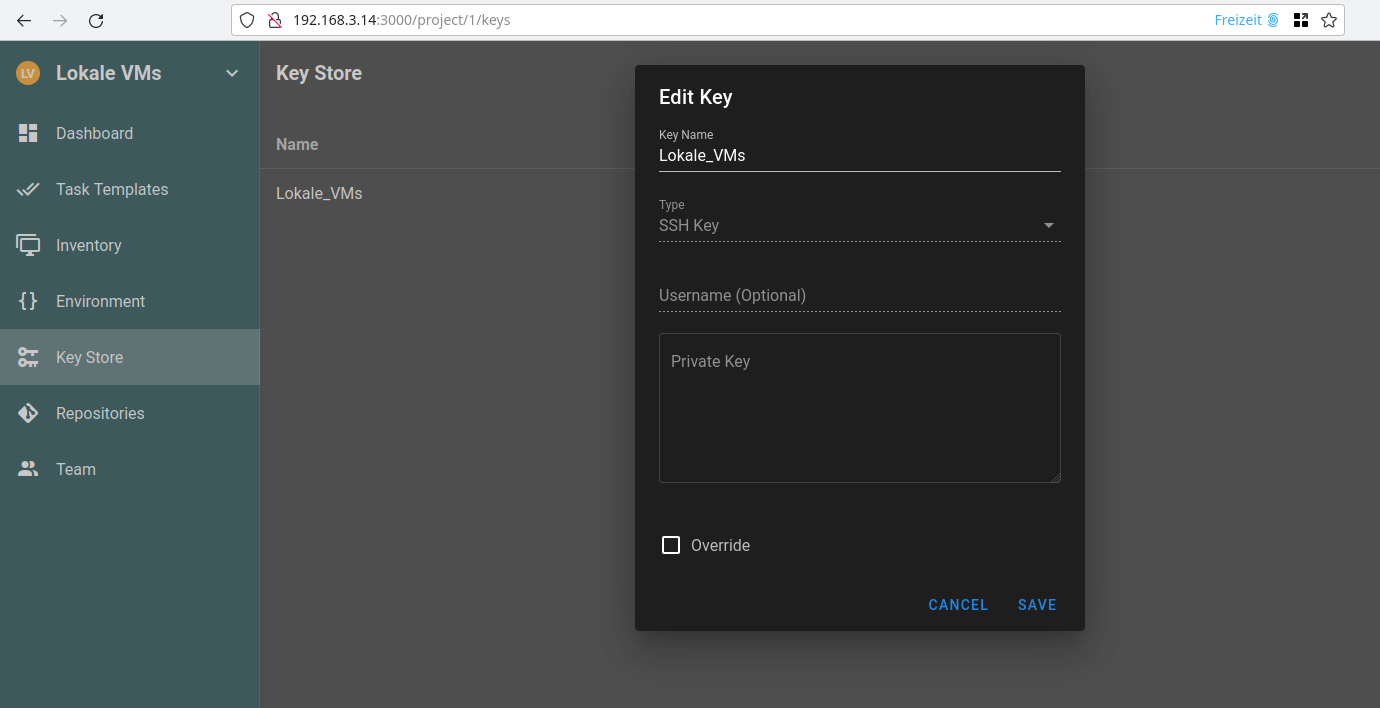
Wir geben ihm einen Namen, wählen SSH Key aus, als Username wählen wir root und geben den Private Key des Semaphore Servers ein.
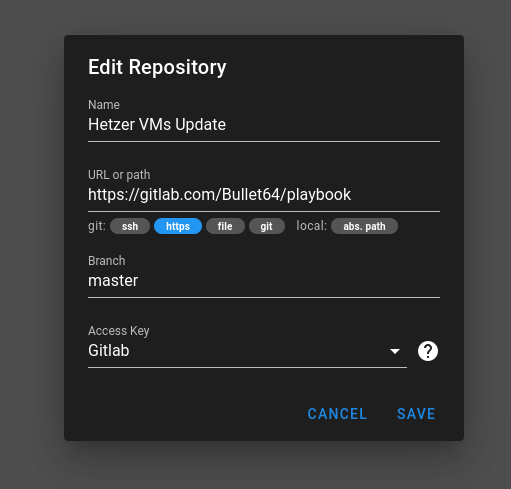
Repositories
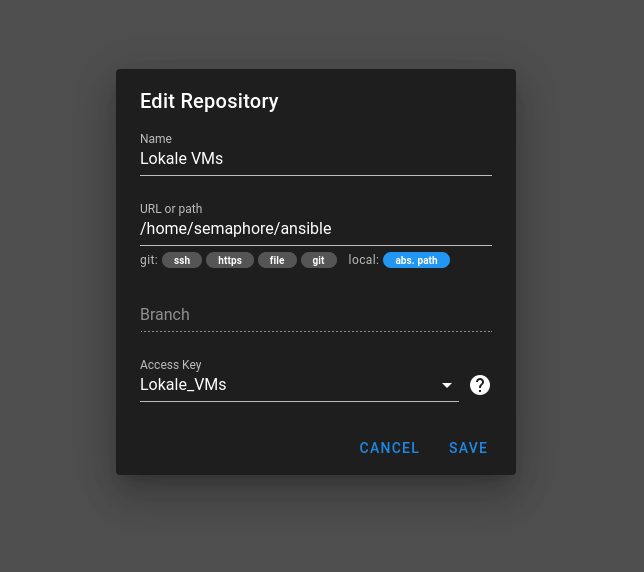
Wir geben ihm einen Namen. Der Pfad zeigt auf einen Ordner im Home-Verzeichnis des Users semaphore. Ich nenne das hier im Beispiel ansible, dort liegen hinterher die Playbooks usw.
Environment
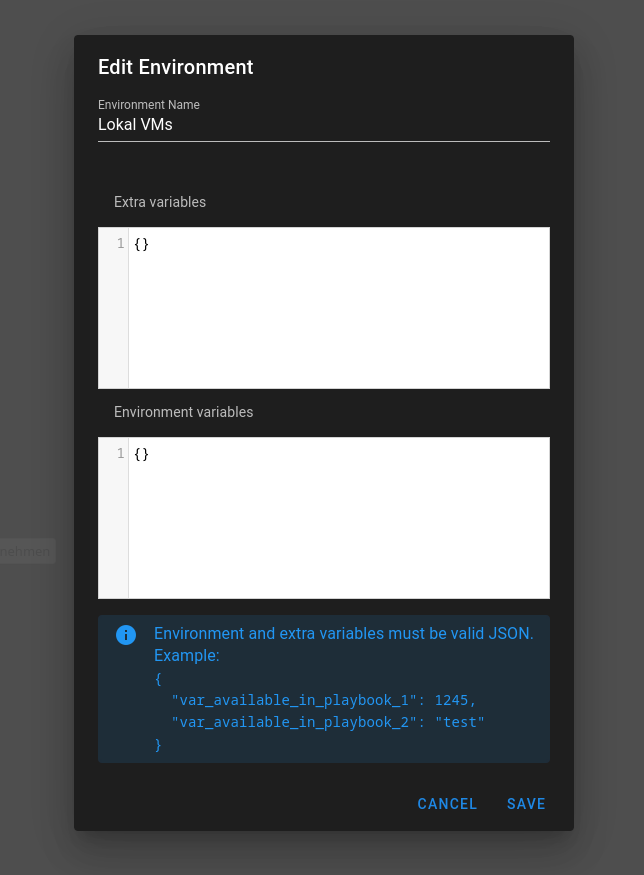
Dort kann man Umgebungsvariablen ablegen. Brauchen wir aktuell nicht, muss aber angelegt sein. Deswegen muss das so aussehen. Also, ohne Inhalt.
Inventory
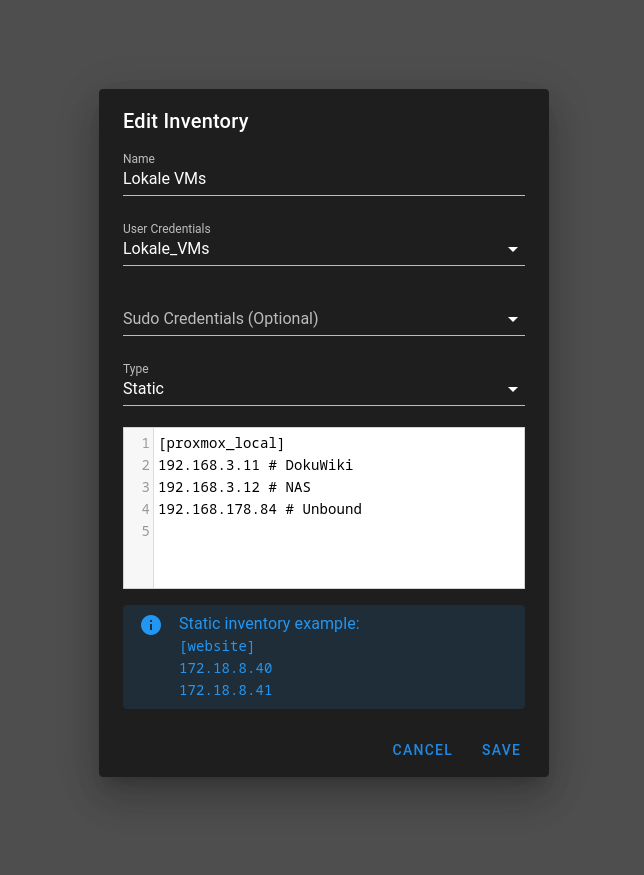
Hier legt man an, welche Server bearbeitet werden sollen. Denke, das ist selbsterklärend. Der Name [Name] kann beliebig sein.
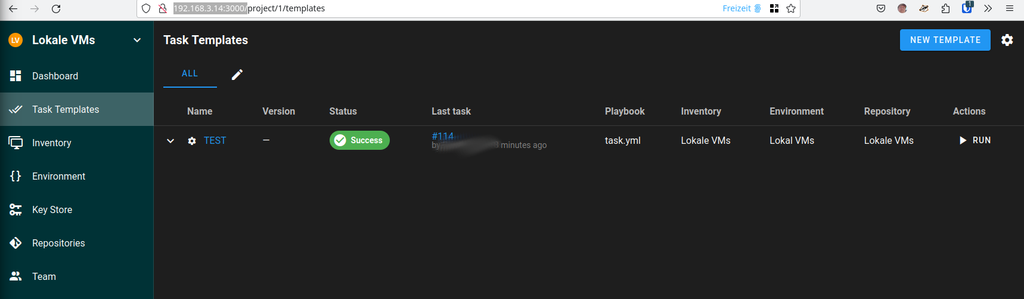
Task Template
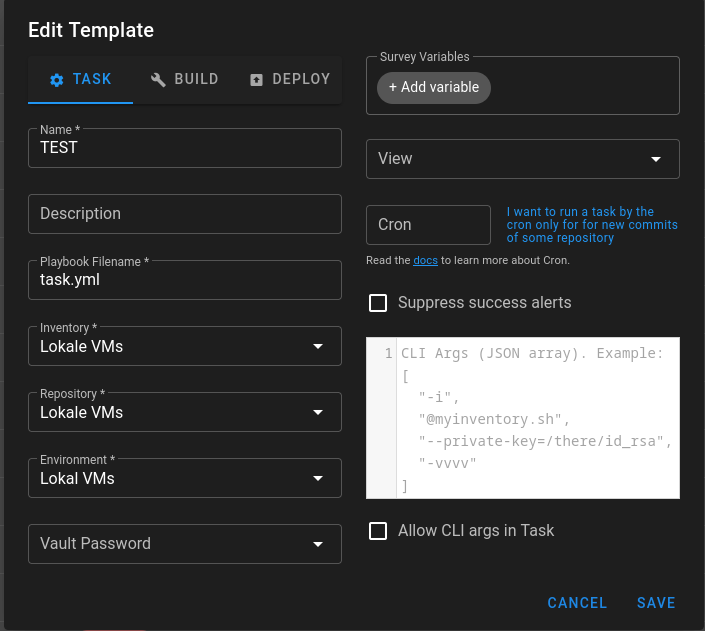
Jetzt könnt Ihr alles auswählen. Das Playbook Filename hat mich etwas Zeit gekostet um zu verstehen, wo das liegt. Da kommt jetzt wieder das Repository zum Einsatz. Der dort hinterlegte Pfad wird jetzt für das Playbook benutzt.
Das Playbook task.yml haben wir noch nicht, kommt noch Das kann man jetzt aber nicht in dem UI anlegen und bearbeiten, wir müssen auf die Konsole des Servers.
Playbook anlegen
Das Playbook muss hier liegen
/home/semaphore/ansible
/home/semaphore/ansible/task.yml
---
- name: My task
hosts: all
tasks:
# Update and install the base software
- name: Update apt package cache.
apt:
update_cache: yes
cache_valid_time: 600
- name: Upgrade installed apt packages.
apt:
upgrade: 'yes'
#register: upgrade
- name: Ensure that a base set of software packages are installed.
apt:
name:
- duf
- needrestart
- htop
# - build-essential
# - curl
# - fail2ban
# - firewalld
# - git
# - needrestart
# - pwgen
# - resolvconf
# - restic
# - rsync
# - sudo
# - unbound
# - unzip
# - vim-nox
state: latest
- name: Check if a new kernel is available
ansible.builtin.command: needrestart -k -p > /dev/null; echo $?
register: result
ignore_errors: yes
- name: No new kernel
ansible.builtin.command: uname -r
when: result.rc == 0
- name: Restart the server if new kernel is available
ansible.builtin.command: reboot
when: result.rc == 2
async: 1
poll: 0
- name: Wait for the reboot and reconnect
wait_for:
port: 22
host: '{{ (ansible_ssh_host|default(ansible_host))|default(inventory_hostname) }}'
search_regex: OpenSSH
delay: 10
timeout: 60
connection: local
- name: Check the Uptime of the servers
shell: "uptime"
register: Uptime
- debug: var=Uptime.stdout
Ich habe die letzten Tage an meinem Playbook gefeilt, die Dokumentation ist riesig. Richtige Hilfe im Netz ist selten, ChatGPT hat auch mehr Blödsinn geschrieben, als Hilfe. Zum Schluss habe ich es aber doch hinbekommen.
Die Tasks
-
Update apt package cache.
Macht das was apt update auch macht, schaut nach neuen Paketen.
-
Upgrade installed apt packages.
Also ein apt upgrade
-
Ensure that a base set of software packages are installed.
Stellt sicher, das man bestimmte Software Pakete auf seinem Server installiert hat.
-
Check if a new kernel is available
Hat apt upgrade einen neuen Kernel installiert? Dazu nutze ich das Tool needrestart. Rückgabewert 0 bedeutet keinen neuen Kernel, Rückgabewert 2 bedeutet, es ist Zeit für einen Reboot. Interessantes Feature von ansible ist, man kann gewisse Dinge auch async machen. Ohne das knallte das Playbook immer mit Failure, weil logischerweise der Server nicht mehr erreichbar war. Spannend.
-
No new kernel
Rückgabe 0
-
Restart the server if new kernel is available
Rückgabe 2
-
Wait for the reboot and reconnect
Wir warten auf alle Server, bis alle Server wieder on sind.
-
Check the Uptime of the servers
Wir schauen nach dem die Server alle wieder on sind, ob sie auch leben ")
-
debug: var=Uptime.stdout
Kontrolle der Uptime.
Fertig!
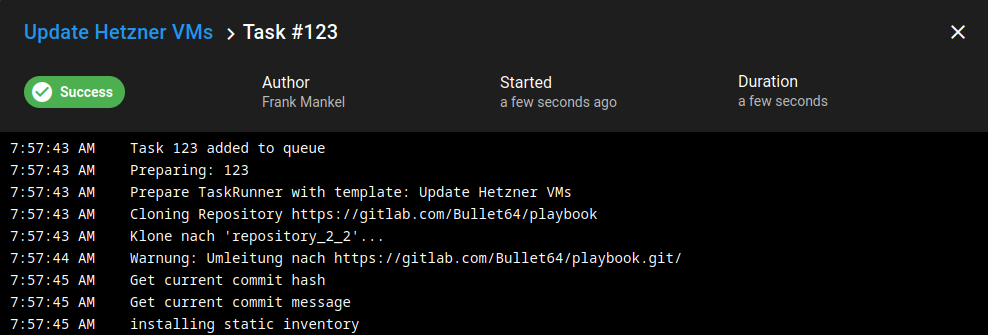
Task Ausgabe
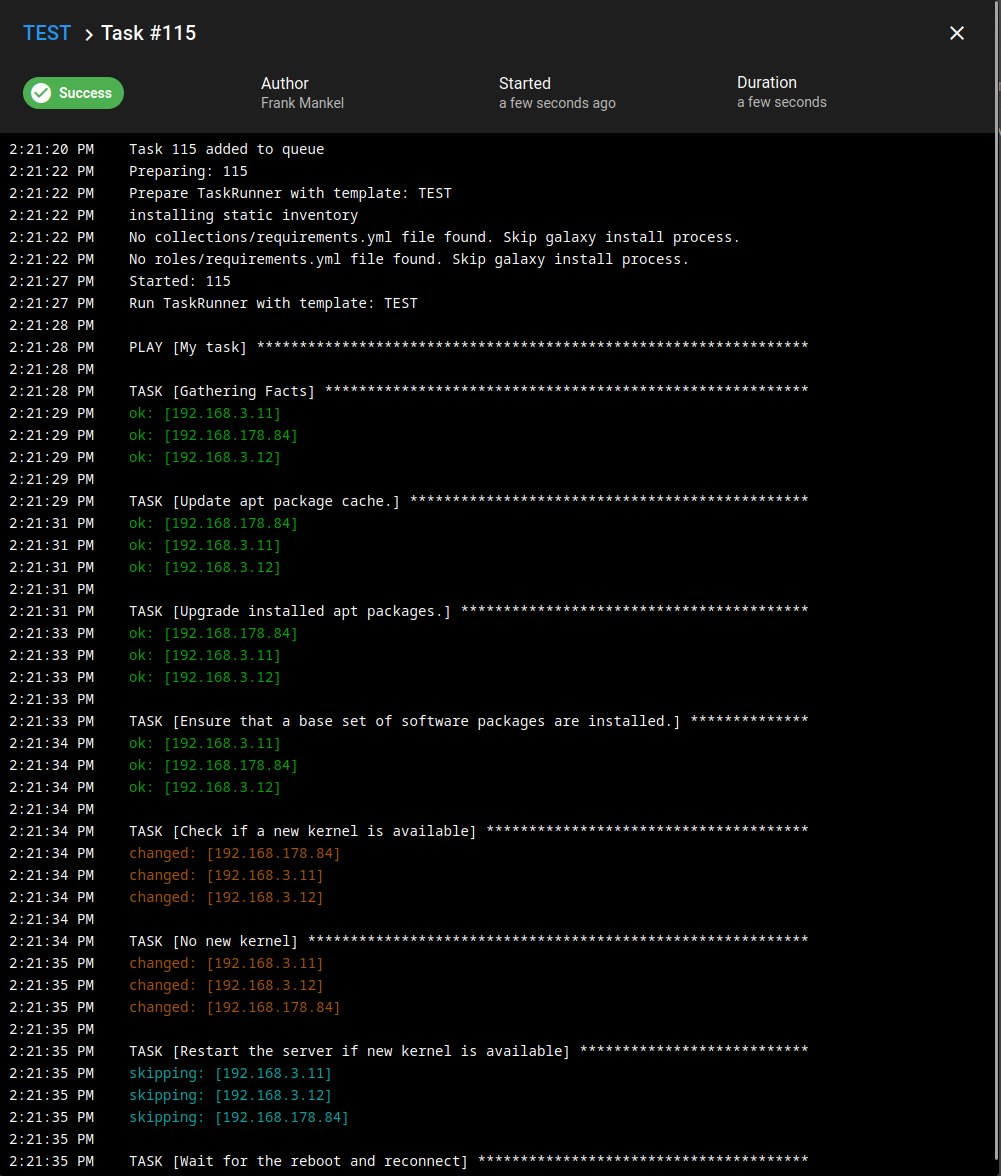
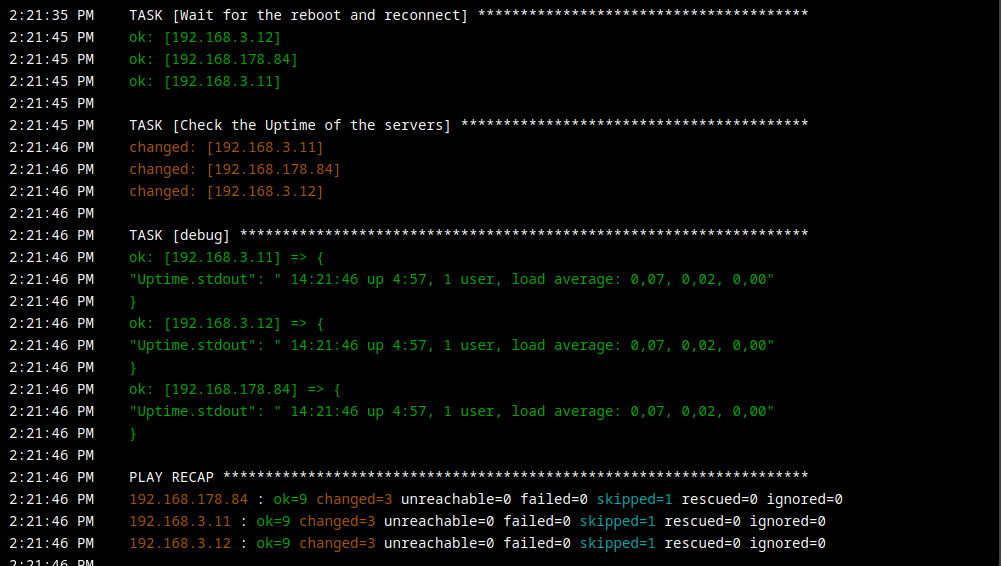
Fazit
Mal wieder ein Tool, was @Nico mir empfohlen hat und was vermutlich aus meinem Leben nicht mehr verschwindet
Hinweise
Für einen Server im Netz fehlen da noch einige Dinge, also bitte so nicht ins Internet. Lokal ist das ausreichend.
Sollte jemand Fehler finden, würde ich mich über eine Korrektur freuen. Man kann immer nur dazu lernen.
Viel Spaß mit dem Tool!